MLOps Made Simple
14 December 2022
An excerpt from an article written by Sree, published in ‘AI in Plain English’ Journal.
My list of vital basics when it comes to handling MLOps in the real world.
Hey there, if you’re reading this article, chances are you’ve come across MLOps (Machine Learning Operations) countless times or maybe even had your fair share of frustration managing an abundance of productionized models on your systems.
For organizations ranging from small to medium, or even medium to large, it’s highly likely that you and your team are responsible for the models that have been built and put into production. This is a common scenario across industries, especially in APAC, where having a dedicated MLops team might not be the norm. Instead, you and your team are the go-to experts for everything related to ML. If you’ve ever found yourself in this situation, let’s dive right in.
Now, I don’t want to bore you with all those MLOps jargon just for the sake of it. However, by now, you’ve probably realized, like me, that the real challenge in scaling up a machine-learning model arises after crafting a perfect model and deploying it to production. You see, a model that performs well with the current data may not necessarily perform optimally with future data, thanks to various factors. In the real world, we often encounter new anomalies, seasonal patterns, and data quality issues in the target data our model is trying to predict, leading to what we call “model drift.”
But before you start feeling overwhelmed by the ever-growing list of MLOps services, let me share with you the bare minimum essentials that we use at our workplace - and they actually do the job pretty well. So, let’s get started!
Background:
I’m sure many of you have already heard about Google Vertex AI. And if you haven’t, I strongly recommend checking it out - you’ll thank me later! It’s like a one-stop portal within Google Cloud where you can handle the entire deployment and management of your ML projects. Amazon has its own version called Amazon SageMaker, and of course, Microsoft wouldn’t be left behind - they have their own called Microsoft Azure Machine Learning. Setting them all aside, we have many other independent SaaS providers like Valohai who offer impressive solutions at scale. The good news is that once you’re familiar with one of these cloud services, you can easily adapt to the others.
In my experience, I follow seven key phases for any machine learning project: Data Pre-processing and Evaluation, Model Selection, Model Evaluation, Model Improvement, Future Predictions, and Model Deployment and Post-Deployment Processes. And the great thing is that all these phases can be seamlessly executed within any of these cloud services.
Now, let me share my story. I’m responsible for marketing data science and analytics at a medium to large-sized e-commerce group in the Asia-Pacific region. If you’re curious about what I do on a daily basis, feel free to check out this article!
From Slack Huddles to Code Reviews: A Day in the Life of a Lead Marketing Data Scientist
Here, we heavily rely on Google Cloud Storage Buckets and Google BigQuery tables for our entire marketing data science and analytics ecosystem. So, to establish our end-to-end machine learning pipelines, we heavily depend on Google Vertex AI Jupyter Notebooks, which serve as the backbone of our operations. Without further delay, let’s move on to the exciting part - exploring the bare minimums you need to know in MLOps.
Bare Minimums:
In my MLOps stack, I primarily focus on two key components: model management and model monitoring. Let’s explore each of these components in a bit more detail.
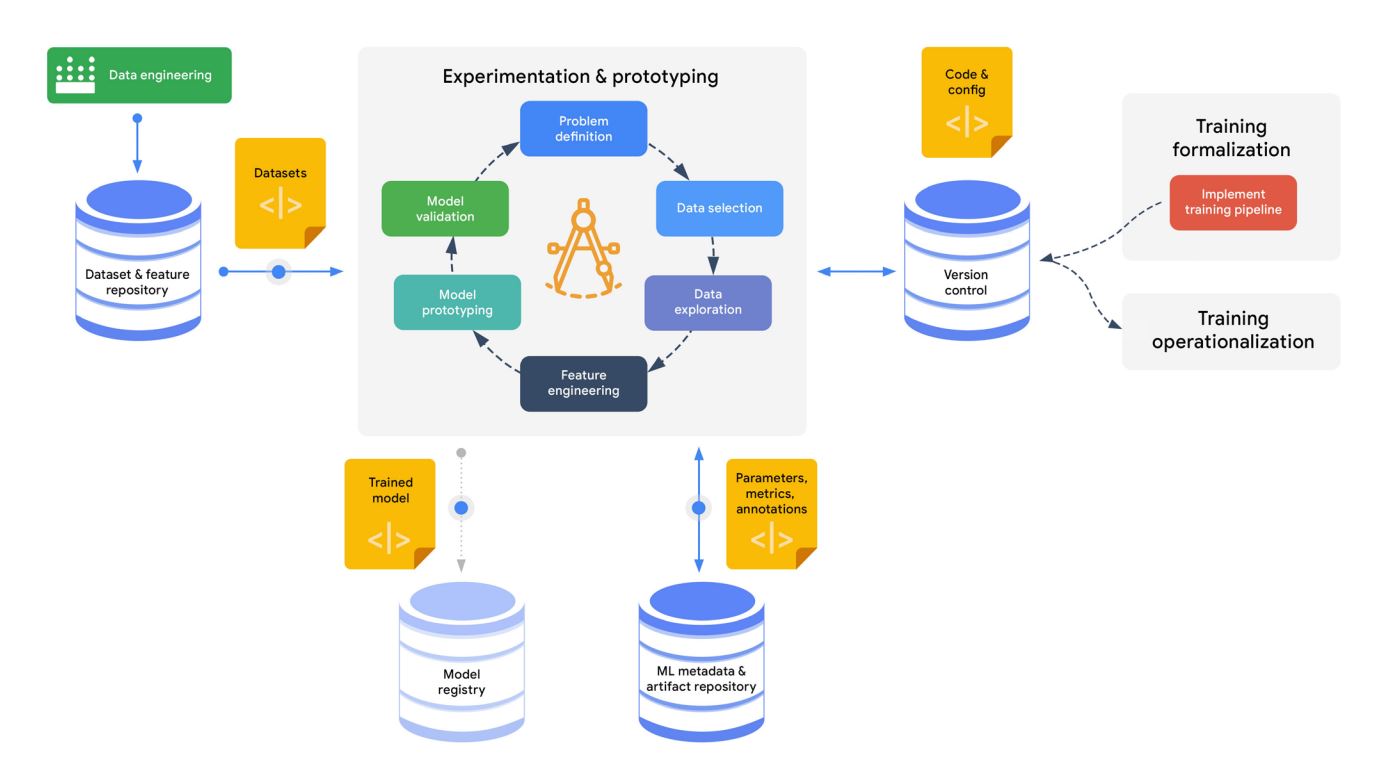
Model Management:
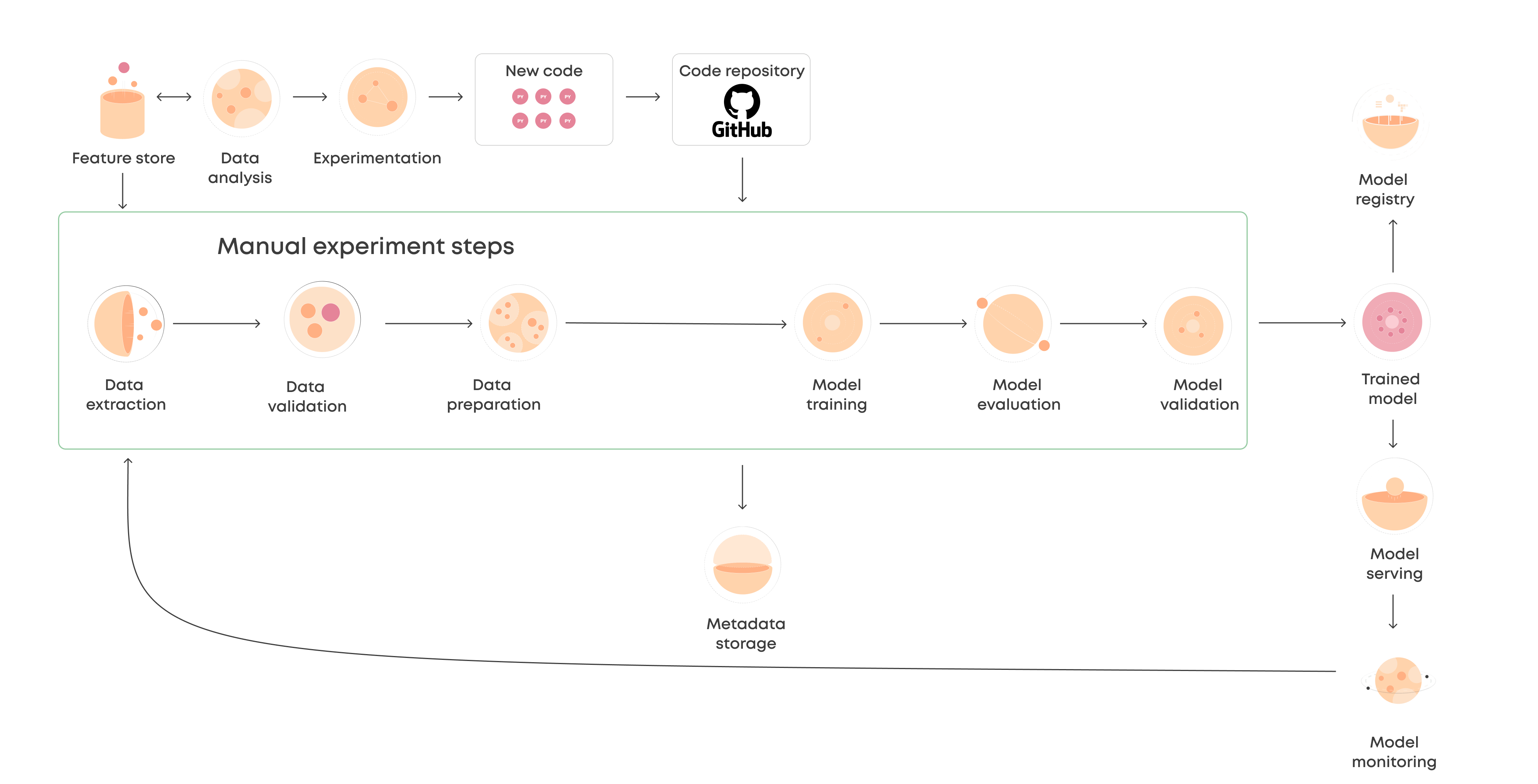
I’m sure many of you can relate to the treasure hunt my team and I often embark on, searching for the right version of a trained model that has been staged, deployed, or retired for a specific business use case. Wouldn’t it be amazing if we could view all of these models in one go? Well, that’s where the model registry comes into play.
Once a model is trained and ready, my first priority is always to send it to the model registry within the Google Vertex AI machine learning pipeline. This step is crucial because it allows us to track different versions of the trained model - a fundamental aspect of my MLOps stack. The Model Registry acts as a central hub where my team can easily locate trained models and view their status, whether they are staged, deployed, or retired.
It provides essential information about each model. As the number of productionized or retired models grows (which tends to happen as the business requests keep pouring in from the leadership), the model registry becomes our go-to hub for clarity on what’s currently running and since when. Establishing the model registry marks the initial significant step in my model management process. It’s the first bare minimum in MLOps.
Model Metadata Stores:
Now, let’s move on to the second part of model management, which involves configuring the model metadata stores. I’m sure many of you, like me, have found ourselves in situations where we’re trying to recall which set of hyperparameters we used earlier that resulted in better performance (after countless experiments). This is where model metadata stores come into play - they’re like the storeroom of all the training and test data, as well as the source code and hyperparameters that fueled these models.
In Vertex AI, ML model metadata is stored as a schematic graph, helping us track various aspects. Firstly, we can trace back the training or test data that was used to create the models. Secondly, we can delve into the source code and hyperparameters that were employed during the training process. Lastly, we have the opportunity to monitor model performance evaluation metrics and track artifacts generated by the model, such as the results of batch predictions at any given time. Therefore, configuring the model metadata stores represents the second crucial step in my model management process.
By establishing a model registry and configuring model metadata stores, we lay the foundation for effective model management. These steps provide us with the necessary tools to track and organize our trained models, ensuring better visibility and control throughout the ML lifecycle.
Model Monitoring
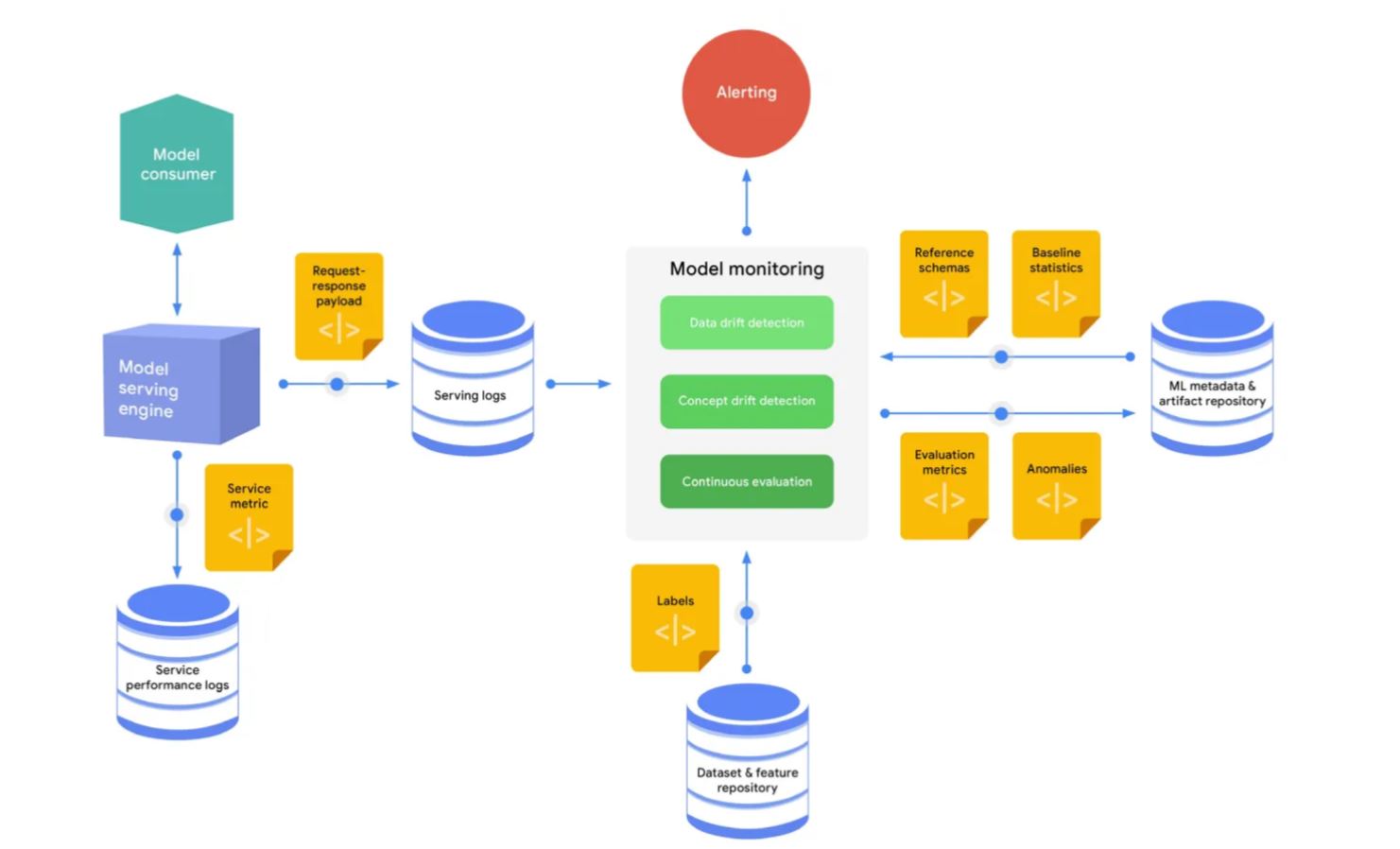
Once I’ve configured the model registry and model metadata stores and trained the model, the next step is selecting the best-trained model for the business use case and deploying it to the Vertex API endpoint for batch predictions.
As seasoned ML practitioners know, the fairy tale stories of “titanic” and “IRIS” datasets hardly exist in the real world. As I mentioned earlier, the model that performs well with current data may not perform well with future data due to various reasons. In the real world, we often encounter new anomalies, seasonal patterns, and data quality issues in the target data that our model is trying to predict, leading to model drift. And when you have a surplus of productionized models, monitoring each one of them feels like another full-time job! This is where system-generated model monitoring mechanisms come into the picture.
Google Vertex AI provides pre-built model monitoring mechanisms, including a series of model monitoring CRON jobs, to assess the performance of our machine learning models. We can keep track of key performance evaluation metrics such as Accuracy, Recall, F1 Scores, ROC-AUC curves, MSE, RMSE, and more. Additionally, we can monitor descriptive statistics of the target dataset, such as minimum, maximum, mean, median, uniqueness, and variable correlations. Visualizing these statistics helps us observe how they change over time.
In my experience, there are two primary ways to identify model drift. First, through regular model analysis, where we notice discrepancies in the model’s performance. Second, through the built-in model monitoring alert mechanisms. From an MLOps perspective, one of the most valuable features of Google Vertex AI, or any other CI/CD ML pipeline vendor, is the model monitoring alert system. This system automatically notifies us if it detects anomalies in the target dataset or if there are statistically significant changes in the distribution of observations over time.
If I detect model drift, the most common approach is to retrain the model using new data. The updated model then becomes a new version in both the model registry and the model metadata stores. Subsequently, it is deployed through the Vertex API endpoints. This initiates the next phase of ML model monitoring, creating an automated and continuous feedback loop for the machine learning model.
By leveraging the model monitoring mechanisms provided by these cloud services, we can effectively detect and address model drift, ensuring that our models remain accurate and reliable in ever-changing real-world scenarios.
Monitoring and mitigating model drift, whether it’s concept drift or data drift, are vital elements of MLOps. They ensure that the machine learning model remains relevant and effective in addressing the business problem at any given time.
Tail end
In addition to configuring the model registry, model metadata stores, and model monitoring alert mechanisms, the two other components that actively contribute to my MLOps stack are nothing but the feature stores and Git versioning systems. These components allow me to version control features, labels, and source codes, while also facilitating the establishment of an end-to-end Continuous Integration & Deployment Machine Learning pipeline (CI/CD pipeline) for batch predictions within the marketing spectrum of the business.Tail end In addition to configuring the model registry, model metadata stores, and model monitoring alert mechanisms, the two other components that actively contribute to my MLOps stack are nothing but the feature stores and Git versioning systems. These components allow me to version control features, labels, and source codes, while also facilitating the establishment of an end-to-end Continuous Integration & Deployment Machine Learning pipeline (CI/CD pipeline) for batch predictions within the marketing spectrum of the business.
I understand that this list may not be exhaustive, as MLOps services and requirements continue to evolve every day. However, for now, we are delighted to have achieved this feat, and I’m confident that it covers most of the bare minimums for our ML project requirements. I hope this write-up serves as a helpful starting point for you to explore this avenue, especially if you have been hesitant to dive in.
In conclusion, I encourage all entry-level juniors and aspiring data scientists to embrace the world of MLOps. It presents a vast realm of opportunities to enhance your skills, contributes to impactful projects, and shape the future of data-driven decision-making. Embrace the challenges, stay curious, and keep learning. The possibilities are endless!
By the way, if you enjoyed reading this article and would like to explore more of my stories, feel free to check out my profile. Stay tuned for more insightful content on MLOps, data science, and beyond. Keep exploring, keep growing, and embrace the exciting era we are in!
About the Author
Sree is a Marketing Data Scientist and seasoned writer with over a decade of experience in data science and analytics, focusing on marketing and consumer analytics. Based in Australia, Sree is passionate about simplifying complex topics for a broad audience. His articles have appeared in esteemed outlets such as Towards Data Science, Generative AI, The Startup, and AI Advanced Journals. Learn more about his journey and work on his portfolio - his digital home.