Web Scraping in R
Geospatial Competitor Analysis
An excerpt from an article written by Sree, published in ‘The Startup’ Journal.
Objective
To fetch the latest product prices that have been hosted on the competitor’s website programmatically.
Details
For the purpose of demonstration, let’s look into the websites of WeWork and Regus; two leading players in the co-working industry who competes among each other to serve hot desks, dedicated desks, and private offices across the globe. Let’s try to scrap their websites in California to retrieve the latest product price listings programmatically.
There were four milestones to accomplish the objective:
1) Web scraped Regus sites using httr/rvest packages.
2) Cleaned the dataset and incorporated geospatial co-ordinates.
3) Repeated the steps 1 & 2 for WeWork websites.
4) Embeded R script in Power BI and visualized the final output.
Phase 1: Web scraped Regus sites using httr/rvest packages
- Step 1.1. Imported Libraries: Imported all the relevant libraries upfront.
library(tidyverse)
library(rvest)
library(revgeo)
library("opencage")
library(dplyr)
library(sqldf)
library(formattable)
library(stringr)
library(ngram)
library(httr)
library(rlist)
library(jsonlite)
library(lubridate)
library(splitstackshape)
- Step 1.2. Regus Location API: Extracted the co-working locations in California from Regus location API using httr package.
options(warn=-1)
time <- Sys.time()
location_data_final <- data.frame()
url <- "https://www.regus.com/api/search/centres"
resp <- GET(url)
http_type(resp)
jsonRespText<-content(resp,as="text")
jsonRespParsed<-content(resp,as="parsed")
regus_locations <-fromJSON(jsonRespText)
regus_locations <- regus_locations %>%
select (CenterNumber
,CenterName
,Latitude,Longitude
,FormattedAddress
,CenterCity)
Phase 2: Cleaned the dataset and incorporated geospatial co-ordinates.
- Step 2.1. Reverse Geocoding: Used revgeo package to identify the street, city, state, and country of the lat, lng coordinates.
reverse_geocode<- revgeo(
longitude=regus_locations$Longitude
,latitude=regus_locations$Latitude
,output='frame')
reverse_geocode <- cbind(regus_locations
, reverse_geocode)
regus_locations_full <- regus_locations %>%
inner_join (reverse_geocode,
by = c("CenterNumber"))
regus_california <- regus_locations_full %>%
filter( country == "United States of America"
,State == "California")
- Step 2.2. Regus Product Pricing API: Extracted the Regus co-working product pricing per location in California. Finally wrapped the whole process of data extraction with a ‘for loop’.
dedicated_desk <- data.frame()
for (i in 1: as.integer(
regus_california %>% summarise(n()
)))
{
#Status Code 500 Path
url <- paste("https://www.regus.com/ecommercevo/price?
productType=platinum&daysLength=30&monthLength=1
&startDate=", Sys.Date(),"&countryCode=US
¢reNumber=",regus_california$CenterNumber[i]
, sep ="")
resp <- GET(url)
if(resp$status_code == 500){
url <- paste("https://www.regus.com/ecommercevo/price?
productType=platinum&monthLength=1&startDate="
, Sys.Date()," &countryCode=US¢reNumber="
, "&_=",as.integer(as.numeric(Sys.time()))
,924,sep ="")
resp <- GET(url)
jsonRespText<-content(resp,as="text")
vo_list <-fromJSON(jsonRespText)
if(!is.null(vo_list$Price))
{
dedicated_desk_temp <- as_data_frame(
vo_list$Price)%>%rename(dedicated_desk_price=value)
dedicated_desk_temp$center_number <-
as.integer (regus_california$CenterNumber[i])
}
if(is.null(vo_list$Price))
{
dedicated_desk_temp <- as_data_frame( "$0" ) %>%
rename( dedicated_desk_price =value)
dedicated_desk_temp$center_number <-
as.integer(
regus_california$CenterNumber[i])
}
dedicated_desk <- rbind(dedicated_desk
, dedicated_desk_temp)}
else if (resp$status_code == 200)
{
jsonRespText<-content(resp,as="text")
vo_list <-fromJSON(jsonRespText)
if(!is.null(vo_list$Price))
{
dedicated_desk_temp <- as_data_frame(
vo_list$Price) %>% rename(
dedicated_desk_price=value)
dedicated_desk_temp$center_number <-
as.integer (
regus_california$CenterNumber[i])
}
if(is.null(vo_list$Price)){
dedicated_desk_temp <- as_data_frame( "$0" ) %>%
rename(dedicated_desk_price =value)
dedicated_desk_temp$center_number <-
as.integer (regus_california$CenterNumber[i])
}
dedicated_desk <- rbind(dedicated_desk
, dedicated_desk_temp)
}}
regus_california <- regus_california %>%
left_join(
dedicated_desk,
by = c("CenterNumber" = "center_number"))
Phase 3: Web scraped & Cleaned WeWork datasets
- Step 3.1. WeWork Product Pricing API: Extracted the WeWork co-working product pricing per locations in California. Finally wrapped the whole process of data extraction with a ‘for loop’.
url <- c("https://www.wework.com/l/sf-bay-area--CA")
location_data_final <- data.frame()
for(i in url){
webpage <- read_html(i)
location_data <-
html_nodes(webpage
, ".mb0, .ray-card__content") %>%
html_text() %>%
enframe()
location_data$urlid <- i
location_data_final <- rbind(
location_data_final
,location_data)}
wework_1.a <- location_data_final %>%
select (value) %>%
mutate (row_num = row_number()
,filter_check = row_num%%2==0)
%>% filter(filter_check == "TRUE")%>%
select (-filter_check) %>%
select(-row_num) %>% rename(
site_name_short = value)
wework_1.b <- location_data_final %>%
select (value) %>% mutate (
row_num = row_number(),filter_check =
row_num%%2!=0 ) %>% filter(
filter_check == "TRUE")%>% select (
-filter_check)%>% select(-row_num)
wework_1 <- cbind(wework_1.a, wework_1.b)
- Step 3.2. Cleaned WeWork dataset: Cleaned the raw dataset by extracting the required information out of the WeWork dataset
wework_1 <- wework_1 %>% rename (
full_info = value) %>% mutate(
full_info = str_squish (full_info))
wework_1 <- sqldf("select * from wework_1
where full_info not like '%Pricing for this location
is not yet available%'")
wework_1 <- sqldf("select * from wework_1
where full_info not like '%Move in ahead of the curve
with special pre-opening rates%'")
wework_1.1 <- str_split_fixed(wework_1$full_info,
"Starting prices", 2) %>% as.data.frame()
wework_1.2 <- as.data.frame(wework_1.1$V2) %>%
rename (value = `wework_1.1$V2`)
wework_1.2 <- separate(wework_1.2, value,
c("Private Office", "Price"),
sep = "Private Office")
wework_1.2 <- separate(wework_1.2, Price,
c("private_office_price"
, "Price"), sep = "Dedicated Desk")
wework_1.2 <- separate(wework_1.2, Price,
c("dedicated_desk_price"
, "hot_desk_price"), sep = "Hot Desk")
wework_interim <- cbind(wework_1, wework_1.1
, wework_1.2)
%>% select(-full_info,-V2)
%>% rename(site_name = V1)
wordcount_final <- data.frame()
for(i in 1: nrow(wework_interim))
{
wordcount_temp <-
enframe ( wordcount
(wework_interim$site_name_short[i]) ) %>%
select (value)
wordcount_final <- rbind(wordcount_final
, wordcount_temp)
}
wework_pricing <- cbind(wework_interim
, wordcount_final) %>% rename(
word_count= value) %>% select (-`Private Office`)
%>% mutate(building_name =
word(site_name, word_count+1, -1))
%>% select(-word_count)
%>% mutate(site_name = building_name
,date_time_Stamp = format(Sys.time()
, "%d-%m-20%y"),country = "United States"
,company = "wework", currency_name = "US Dollar"
, currency_short = "USD"
, web_url = "https://www.wework.com/l/united-states")
- Step 3.3. Reverse Geocoding: Used revgeo package to identify the street, city, state, and country of the lat, lng co-ordinates.
output_final_lat <- data.frame()
output_final_lng <- data.frame()
output_final_state <- data.frame()
for (i in 1:length(wework_pricing$site_name))
{
output_temp <- opencage_forward(
placename = wework_pricing$site_name[i]
, key = "d3f30e7282414d52ba36461e84613c34"
)
output_final_lat <- bind_rows (
output_final_lat, enframe(
output_temp$results$geometry.lat[[1]]
))
output_final_lng <- bind_rows (
output_final_lng, enframe(
output_temp$results$geometry.lng[[1]]
))
output_final_state <- bind_rows (
output_final_state,
enframe( output_temp$results$components.state[[1]]
))}
wework_pricing$lat <- output_final_lat$value
wework_pricing$lng <- output_final_lng$value
wework_pricing$state <- output_final_state$value
reverse_geocode<- revgeo(
longitude=wework_pricing$lng,
latitude=wework_pricing$lat,
output='frame')
wework_pricing <- wework_pricing %>%
mutate(
street_name = word(site_name, 2, 3),
city = reverse_geocode$city,
postcode = reverse_geocode$zip
)
Phase 4: Embeded R script in Power BI and visualized the final output:
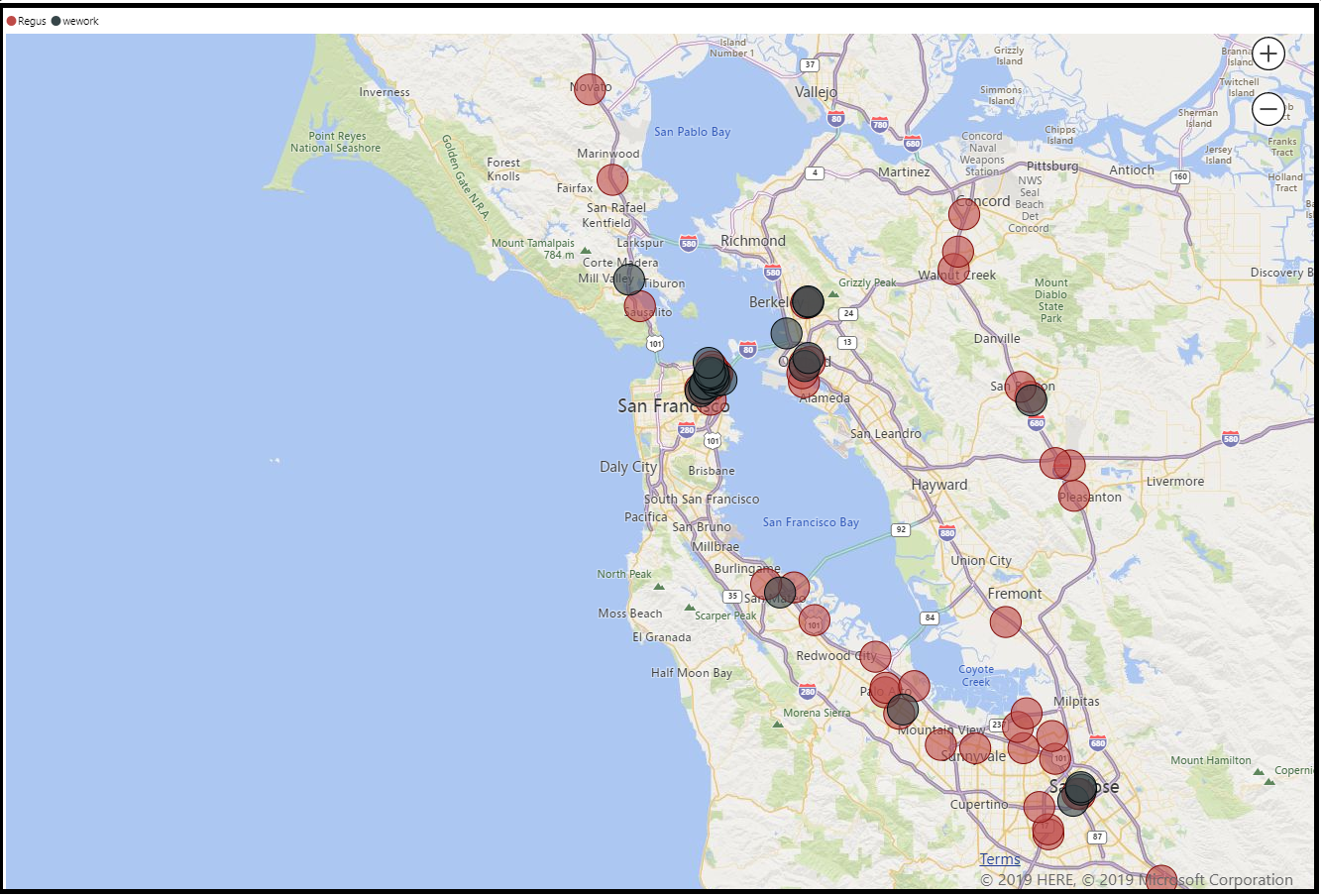
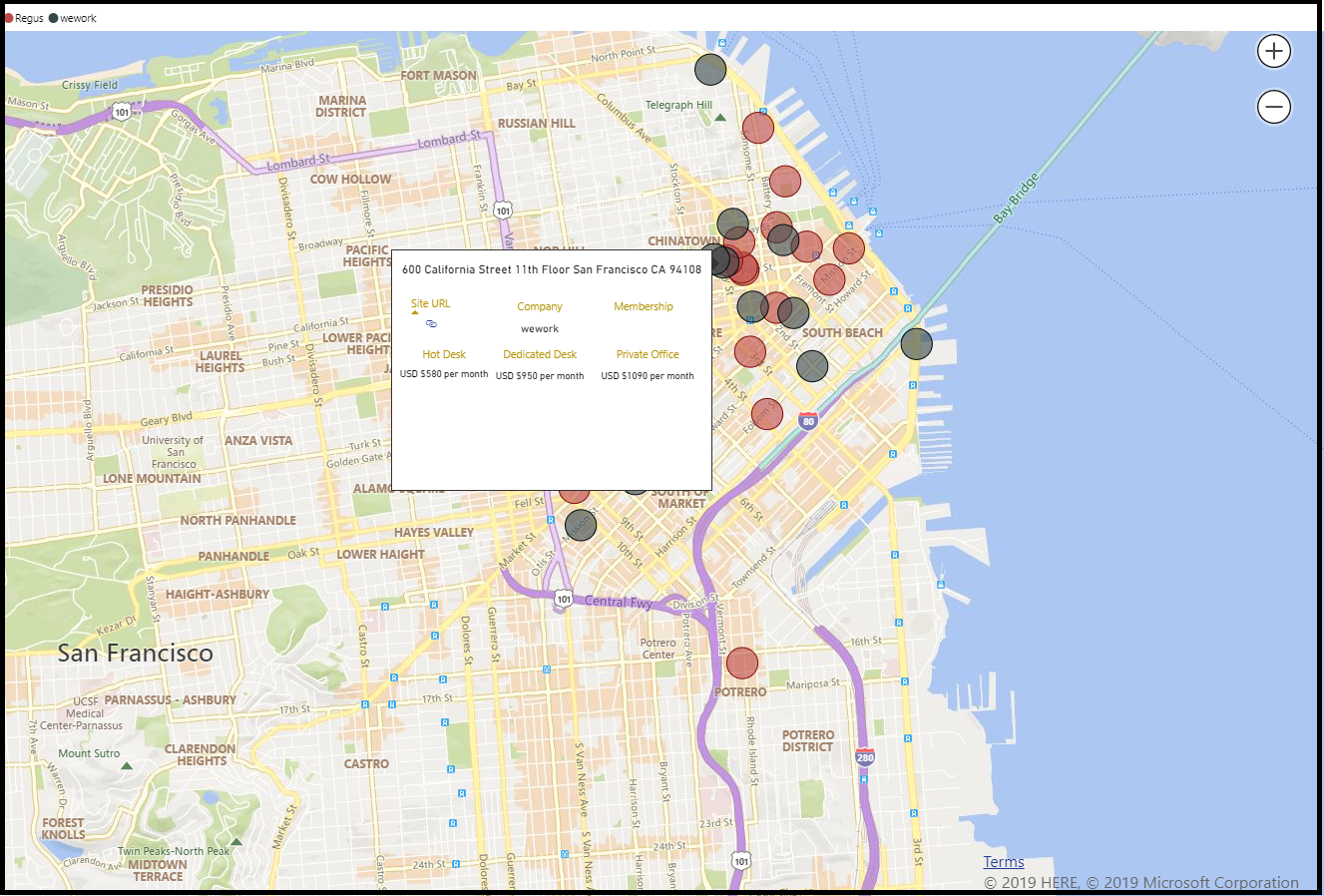
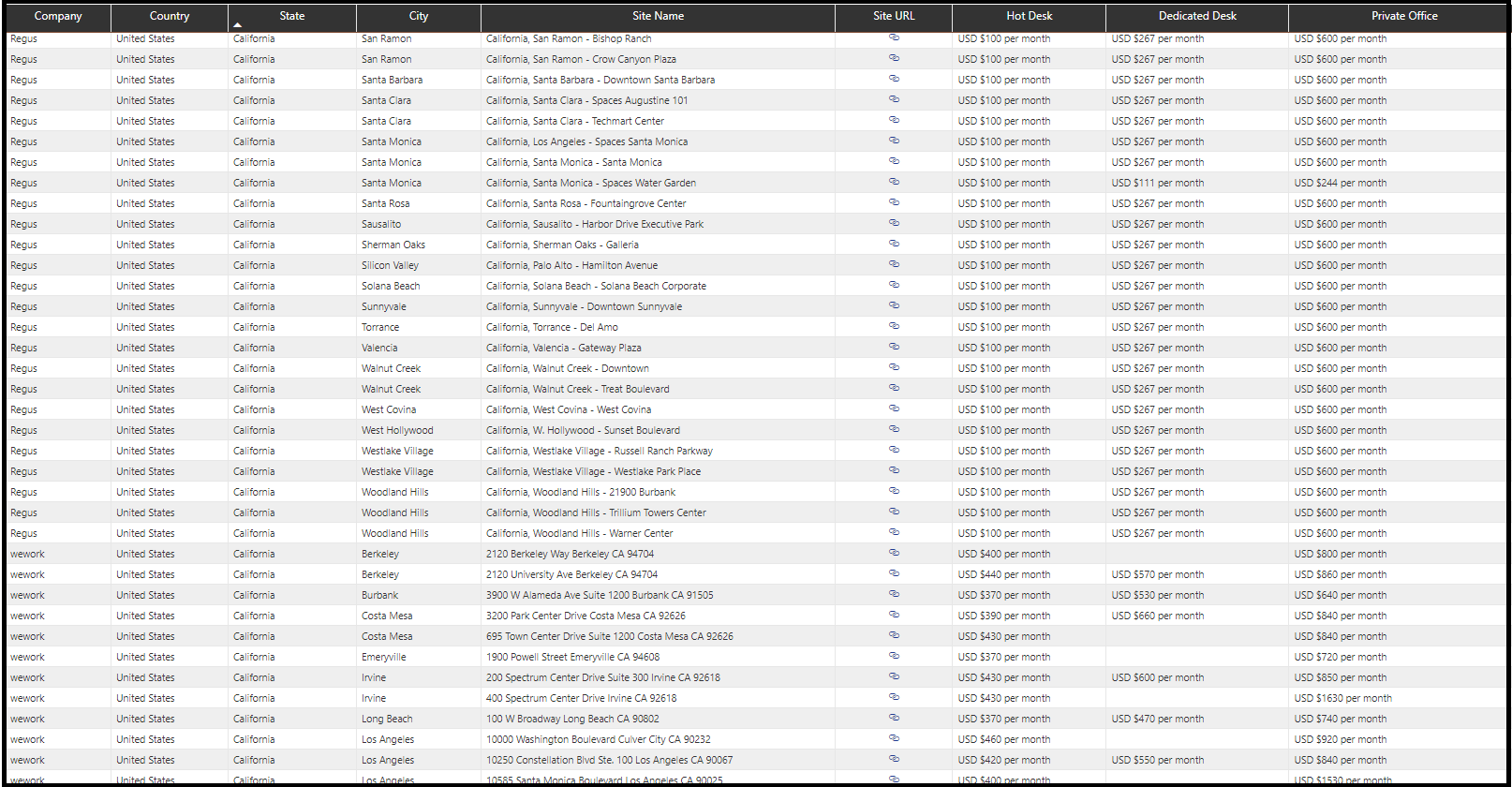
Conclusion
So, in a nutshell, we have successfully extracted the price listings per product per location of two competitors using the web scraping techniques in R programming. Finally, we visualized the output on a geospatial scale to build the data story.
What’s Next?
This is just the starting point of a journey to endless possibilities in competitor intelligence. We could do so much more with the extracted data like the following:
1) Expand the web harvesting technique to build and analyze the trend globally.
2) Automate the whole process of data extraction to build a real-time product pricing model.
3) Feed the daily product price listings into cloud storage (S3/Google Cloud) to monitor the competitor’s daily price fluctuations in a BI platform.
4) Aggregate the price listings per product per location over a period of time to reap insights from the week on week/ month on month/ year on year analysis.
5) Auto-compute the avg. product price per city to see if we are underpriced or overpriced in comparison to the competitor’s price listings at any point in time.
GitHub Repository
I have learned (and continue to learn) from many folks in Github. Hence sharing my entire R scripts and Power BI file in a public GitHub Repository in case if it benefits any seekers online. Also, feel free to reach out to me if you need any help in understanding the fundamentals of web scraping in R. Happy to share what I know:) Hope this helps!
About the Author
Sree is a Marketing Data Scientist and seasoned writer with over a decade of experience in data science and analytics, focusing on marketing and consumer analytics. Based in Australia, Sree is passionate about simplifying complex topics for a broad audience. His articles have appeared in esteemed outlets such as Towards Data Science, Generative AI, The Startup, and AI Advanced Journals. Learn more about his journey and work on his portfolio - his digital home.